
📂 목차
📚 본문
운영체제 커널의 기능
- 쉘: 명령어 라인을 읽어 필요한 시스템 기능을 실행
- 커널: 운영체제의 핵심 기능들이 모여있는 프로그램
메모리 관리 기본
- 가상 메모리: 실제 메모리 주소가 아닌 가상 메모리주 소를 부여하여 가상 주소 범위를 가상 주소 공간, 물리 주소 범위를 물리 주소 공간이라고 한다.
- 메모리 관리 장치(MMU): CPU가 메모리에 접근하는 것을 관리하는 컴퓨터 하드웨어(가상 주소 -> 실제 주소 매핑)
- 메모리 관리자: 기억 장치의 어느 부분이 사용 중인지 아닌지 여부 판단
메모리 관리 기법
- 반입 기법: When 을 결정, 요구 반입 기법, 예상 반입 기법(예측하여 미리 적재)
- 배치 기법: Where 을 결정, 최초 적합, 최적 접합(가장 크기가 비슷), 최악 적합
- 할당 기법: How 를 결정, 연속 할당, 분산 할당
- 연속 할당
- 단일 분할 할당: 오버레이, 스와핑
- 다중 분할 할당: 고정 분할 할당, 동적 분할 할당
- 분산 할당
- 페이징
- 세그멘테이션
- 페이징/세그멘테이션
- 연속 할당
- 교체 기법: Who 를 결정, Swap In/Out, FIFO, LRU, LFU
⭐️ 페이징
정해진 페이지의 크기에 따라 프로세스를 ‘일정하게’ 분할하여 주기억 장치에 분산된 공간에 적재하여 실행하는 방법이며, 프레임은 실제 물리 주소 공간에서 사용할 분산된 공간 각각을 말한다. 페이지 수와 일치해야 한다.
논리 주소는 페이지 번호(p) 와 변위(d) 로 구성되어 있고, 페이지 테이블에서 실제 메모리 기준 주소를 찾고 변위를 더해 물리 메모리 주소(프레임의 시작 주소)를 결정하게 된다.
- 페이지 크기가 작을 경우: 많은 페이지의 사상 테이블 공간 필요, 내부 단편화가 줄지만 매핑 속도가 늦어짐, 디스크 접근 횟수가 많아져 I/O Bound Time 증가
- 페이지 크기가 클 경우: 테이블 크기가 작아져 주기억 장치의 공간이 절약, 매핑 속도가 빨라지지만 페이지 단편화가 증가하게 된다.
⭐️ 세그멘테이션
프로세스를 가변적인 크기의 블록으로 나누고, 메모리를 할당하는 기법이고, 필요한 만큼의 크기를 메모리에 배치하기 때문에 내부 단편화가 낮아지지만 외부 단편화가 증가한다.
주소 변환 과정은 다음과 같다.
- 논리 주소 s(세그먼트 번호), d(변위)가 주어짐
- s를 통해 segment table 에서의 limit, base 를 확인
- base는 기준 주소이고 이는 물리 주소 공간에서 0에서의 offset이다.
- 읽을 base + d 의 값이 유효한지를 보아야 하기 때문에 d < limit 인지 확인한다.
- 참이라면 base + d 로 물리 메모리에 접근한다.
페이징/세그멘테이션
하나의 세그멘트를 정수 배의 부분 페이지로 다시 분할하는 방식, 세그멘트 안에 페이징이 있음
LFU(Least Frequently Used) 알고리즘
FIFO, LRU 생략
사용된 횟수를 확인해 참조 횟수가 가장 적은 페이지를 선택
예시
참조 스트링: 2 3 1 3 1 2 4 5 | 참조 스트링 | 2 | 3 | 1 | 3 | 1 | 2 | 4 | 5 | |—–|—–|—–|—–|—–|—–|—–|—–|—–| | 페이지 프레임 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | | 페이지 프레임 2 | | 3 | 3 | 3 | 3 | 3 | 3 | 3 | | 페이지 프레임 3 | | | 1 | 1 | 1 | 1 | 1 | 1 | | 페이지 프레임 4 | | | | | | | 4 | 5 | | 페이지 부재 | f | f | f | | | | f | f |
메모리 단편화 해결하기
- 내부 단편화: 고정된 분할 영역 외에 남는 공간이 즉, 프로세스를 적재 후 남은 공간을 말한다.
- Slab Allocator: 페이지 프레임을 할당받아서 공간을 작은 크기로 분할하고 메모리 요청 시 작은 크기로 메모리를 할당/해제하는 동적 메모리 관리 기법
- 집약(Coalescing): 인접한 단편화 영역을 찾아서 하나로 통합하는 기법
- 압축(Compaction): 메모리의 모든 단편화 영역을 하나로 압축하는 기법
- 외부 단편화: 할당된 크기가 프로세스 크기보다 작아서 사용하지 못하는 공간
- 버디 메모리 할당(Buddy Memory Allocation): 가장 알맞은 크기를 할당하기 위해 메모리를 $2^n$ 의 크기로 분할하여 메모리를 할당하는 기법
- 집약: 인접한 단편화 영역을 찾아 하나로 통합하는 기법
- 압축: 모든 단편화 영역을 하나로 압축하는 기법
위는 OS 에서 더 자세히 볼 수 있습니다.
Thrashing
어떤 프로세스가 지속적으로 페이지 부재가 발생하여서 실제 처리 시간 보다 페이지 교체 시간이 더 많아지는 현상
Thrasing 해결 방안
- 워킹 세트(Working Set): 각 프로세스가 많이 참조한는 페이지들의 집합을 공간에 계속 상주시킴
- 워킹 세트를 달성하려면 Locality 를 알아야 한다.
- 페이지 부재 빈도(PFF; Page-Fault Frequency): 페이지 부재율의 상한, 하한을 통해 페이지 부재율을 예측하고 조절함
Locality
지역성(국부성, 구역성, 국소성)은 프로세스가 실행되는 동안 일부 페이지만 집중적으로 참조하는 특성이며, 참조 지역성 이라고도 불리며, 3가지 유형이 존재한다.
- Temporal Locality(시간 지역성): 최근 사용한 기억장소들이 집중적으로 액세스하는 현상
- Spatial Locality(공간 지역성): 일정 위치의 페이지를 집중적으로 액세스하는 현상
- Sequential Locality(순차 지역성): 데이터가 순차적으로 액세스 되는 현상
세 개념은 상호배타적인 개념이 아니다. 시간 지역성, 순차 지역성이 동시에 발생할 수도 있고, 다양하다.
메모리 교체 기법 - 프로세스 스케줄링
우선 프로세스 상태 다이어그램을 먼저 보아야 한다.
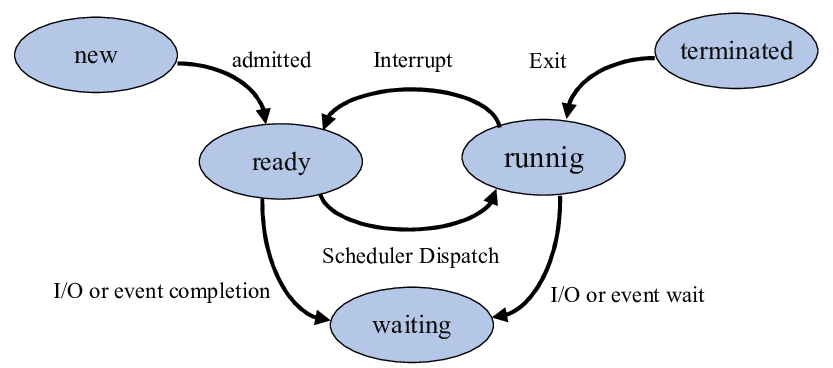
프로세스 구성 요소
- 사용자 작성 코드
- 사용자 사용 데이터
- 스택: 함수 호출 및 인자 값 전송에 사용
- 프로세스 제어 블록: PCB라고 불리고, 프로세스 생성 시 만들어지는 한 프로세스의 전체를 정의한 객체이다. PID, 프로세스 상태, 프로그램 카운터ㅡ 레지스터 저장 영역, 프로세서 스케줄링 정보, 계정 정보, 입출력 상태 정보, 메모리 관리 정보로 구성된다.
IPC: 모듈 간 통신 방식을 구현하기 위해 사용되는 인텊에ㅣ스 집합으로 복수의 프로세스를 수행해서 이뤄지는 프로세스 간 통신을 지원한다.
Thread
프로세스보다 가볍고, 독립적으로 수행되는 순차적인 제어의 흐름이며 실행 단위이다. 프로세스에서 실행 제어만 분리한 실행 단위로 한 개의 프로세스는 여러 개의 스레드를 가질 수 있다.
- 커널 수준 스레드
- 커널이 주체고 커널이 각 스레드를 개별적으로 관리할 수 있고
- 다른 스레드가 입출력 작업이 끝날 때까지 다른 스레드를 사용하여 다른 작업을 진행할 수 있다.
- 단점으로는 오버헤드가 많고, 생성 및 관리하는 것이 느리다.
- 사용자 수준 스레드
- 커널 모드로 전환하지 않기 때문에 인터럽트가 발생할 때 오버헤드가 적고
- 사용자 영역에서 행동하기 때문에 OS 스케줄러의 컨텍스트 스위칭이 없다. 하지만 경량화된 컨텍스트 스위칭을 사용하긴 한다.
- 여러 개의 사용자 스레드 중 하나의 스레드가 시스템 호출 등으로 블록이 걸리면 나머지 모든 스레드 역시 블록됨
- 사용자 수준 스레드는 프로세스 1개당 커널 스레드 1개가 할당됨
프로세스 스케쥴링 기준
- 서비스 시간 = 프로세스가 실행해야 할 총 시간, 프로세스가 CPU에서 실행되는 시간
- 응답 시간 = 프로세스가 처음 CPU를 할당받아 반응하는 시간 - 도착 시간
- 대기시간 = 프로세서에 할당되기 까지 프로세스가 대기 큐에 대기하는 시간
- 반환 시간 = 대기 시간 + 서비스 시간
- 평균 대기시간 = 모든 프로세스의 대기 시간 합을 프로세스 수로 나눈 값(대기시간이 0 인 애도 포함)
- 종료 시간 = 도착 시간 + 반환 시간
- 시간 할당량 = 각 프로세스가 한 번에 CPU를 사용할 수 있는 최대 시간, 주어짐
- 응답률 = $\frac{(대기시간 + 서비스시간)}{서비스 시간}$, HRN 에서 사용
프로세스 스케줄링 유형
- 선점형 스케줄링: CPU 반환시 까지 다른 프로세스 선점 가능
- 비선점형 스케줄링: CPU 반환시 까지 다른 프로세스가 선점 불가
선점형 스케줄링 알고리즘
- SRT(Shortest Remaining Time First): 가장 짧은 시간이 소요되는 프로세스를 먼저 수행
- MLQ(Multi Level Queue): 여러 개의 큐를 이용하여 각 큐는 순위가 있고, 각자 독자적인 스케쥴링을 가짐
- MLFQ(Multi Level Feedback Queue): FCFS 와 RR(Round Robin) 스케줄링 기법을 혼합하여 새로운 프로세스는 높은 우선순위 큐로, 프로세스 실행 시간이 길어질 수록 낮은 우선순위 큐로 이동하며, 마지막은 라운드 로빈 방식을 적용
- RR(Round Robin): 균등한 CPU 점유 시간으로 시분할 시스템에서 활용
비선점형 스케줄링 알고리즘
- Priority
- Deadline
- FCFS(First Come First Served)
- SJF(Shortest Job First)
- HRN(Highest Response Ratio Next)
Deadlock
다중 프로세싱 환경에서 두 개 이상의 프로세스가 특정 자원할당을 무한정 대기하는 상태
발생 조건
- 상호 배제: 자원을 배타적으로 점유하여 다른 프로세스가 그 자원을 사용할 수 없는 상태
- 점유와 대기: 자원을 점유하고 있으면서 또 다른 자원을 요청하여 대기하고 있는 상태
- 비선점: 점유한 자원에 대해 다른 프로세스가 선점할 수 없고 오직 점유한 프로세스만이 해제 가능
- 환형 대기: 두 프로세스가 서로서로 점유와 대기중
해결 방안
- 예방(Prevention): 점유 자원 해제 후 새 자원 요청
- 회피(Avoidance): 안전한 상태를 유지할 수 있는 요구만 수락
- 은행가 알고리즘: 자원 Max - 자원 Allocation = Need 값을 통해 Request $<=$ Need 가 아니면 에러, Request $<=$ Available 가 아니면 대기 상태로 전환, Safe State 인지 확인 후 Unsafe State 면 자원 회수하고 대기를 한다.
- Wound-Wait: 트랜잭션마다 타임스탬프가 있어서
$T_i 의 나이 < T_j 의 나이$ 라면 $T_i$가 $T_j$ 를 Wound 하고($T_j$ 강제 종료 후 Rollback), $T_i$는 자원 획득하여 계속 진행
$T_i 의 나이 > T_j 의 나이$ 라면 $T_i$는 대기한다. - Wait-Die: Wound-Wait 와 같지만 그냥 조건만 반대다.
- 발견(Detection): 시스템의 상태를 감시 알고리즘을 통해 교착 상태 검사
- 자원할당 그래프
- Wait for Graph
- 복구(Recovery): 교착상태가 없어질 때까지 프로세스를 순차적으로 Kill하여 제거
- 프로세스 Kill
- 자원 선점
디스크 스케줄링
- FCFS: FIFO랑 같음
- SSTF: 현재 위치에서 탐색 거리가 짧은 트랙에 대한 요청
- SCAN: 진행 방향이 결정되면 탐색 거리가 짧은 순서에 따라 그 방향의 끝까지 가면서 요청 처리 후 역방향도 그렇게 진행
- C-SCAN: 바깥쪽에서 안쪽으로 움직이면서 가장 짧은 탐색 거리를 갖는 요청을 서비스
- LOOK: SCAN을 기초로 끝까지 안가고 요청까지만 간 후 바꿈
- N-STEP: 대기 중이던 요청들만 서비스, 진행 중 도착한 요청은 한꺼번에 모아서 다음의 반대 진행방향으로 진행할 때 서비스
- SLTF: 섹터 큐잉이라고도 하며, 특정 실린더의 여러 트랙에 대한 요청들을 검사하고 회전지연시간이 가장 짧은 요청부터 처리
전송 매체 접속 제어(MAC; Media Access Control)
통신망에서 공유 매체에 대한 다중 접근 제어가 필요
- CSMA/CD: IEEE802.3 유선 LAN의 반이중 방식(Half Duplex)에서 사용하며, 현재 채널이 사용 중인지 체크하여 사용하지 않을 때 전송하는 매체에 접속하여 단말이 신호 전송함
- CSMA/CA: IEEE802.11 무선 LAN의 반이중 방식(Half Duplex)에서 사용하며, 매체가 비어있음을 확인하고, 충돌을 피하기 위해 임의 시간을 기다린 후 데이터를 전송함
프로토콜 기본요소
- 구문: 데이터 형식, 코딩, 신호 레벨 구성
- 의미: 제어 정보, 에러 처리 등
- 타이밍: 속도 조절, 순서 관리를 위한 요소
OSI 7계층
물데네전세표응
프로토콜 | 계층 | Protocol Data Unit | 대표 Protocol | 대표 장비 | |—————-|———————|—————————–|————————–| | 응용 계층 | Data | HTTP, FTP, SMTP, POP3, IMAP, TELNET, SSH, SNMP | - (소프트웨어 계층) | | 표현 계층 | Data | JPEG, MPEG, SSL/TLS | - (소프트웨어 계층) | | 세션 계층 | Data | RPC, NetBIOS, PPTP | - (소프트웨어 계층) | | 전송 계층 | Segment | TCP, UDP | - L4 Switch | | 네트워크 계층 | Packet | IP, ICMP, IGMP, ARP, RARP, IPsec | 라우터(Router), L3 스위치 | | 데이터링크 계층 | Frame | HDLC, Ethernet, PPP, 프레임 릴레이, ATM, MAC | 스위치(Switch), 브리지(Bridge) | | 물리 계층 | Bit | RS-232, DSL, IEEE 802.3 | 허브(Hub), 리피터, 케이블 |
데이터링크 계층
주요 기술
- VLAN: 물리적 배치와 상관없이 논리적으로 LAN을 구성하여 Broadcast Domain을 구분할 수 있게 해서 성능향상, 보안성 증대를 이룸
- STP(Spanning Tree Protocol): 2개 이상의 스위치가 여러 경로로 연결될 때, 무한 루프를 막기 위해 우선순위에 따라 1개의 경로로만 통신하도록 하는 프로토콜
오류 제어
- 전진 오류 수정(FEC; Forward Error Correction): 오류 검출 및 오류 재전송 요구 없이 스스로 수정
- 해밍 코드 방식: 1비트 오류 검출용이며, 특정 위치에 XOR 연산으로 오류 감지
- 상승 코드 방식: 각 비트가 이전 비트보다 크거나 같게 하여 신호의 순차성으로 오류 감지, 흐름 체크용
- 후진 오류 수정(BEC; Backward Error Correction): 전송 과정에서 오류 발생 시 송신 측에 재전송 요청
- 검출
- 패리티 검사: 1비트 오류 검출용이며, 1의 개수가 홀수가 되도록 추가
- CRC: 다수 비트 오류 검출용이며, 데이터를 이진 다항식으로 보고, 특정 다항식으로 나눈 뒤, 나머지를 코드에 추가
- 블록합 검사: 데이터 블록의 간단한 오류를 검사하며, 일정 크기로 나눈 후에 합계를 계산하여 비교한다.
- 제어: 자동 반복 요청(ARQ; Automatic Repeat reQuest)이 대표적이고 다음과 같은 방식이 있다.
- Stop-and-Wait ARQ: ACK를 받으면 다음 프레임을 전송, NAK을 받으면 재전송
- Go-Back-N ARQ: NAK를 받으면 오류가 발생한 프레임 이후에 전송된 모든 데이터 프레임을 재전송, 즉 NAK로 돌아감
- Selective Repeat ARQ: 연속적으로 데이터를 재전송하고 에러가 발생한 데이터 프레임만 재전송
- 검출
✒️ 용어
Dispatch
Ready Queue 중에서 실행할 프로세스를 선정하여 현재의 실행 중인 프로세스와 교체하는 과정을 디스패치라고 한다.
할당 시간 초과
시간 초과 시 스케쥴러에 의해 프로세스가 PCB에 저장되고 이를 Ready Queue에 저장한다. 해당 프로세스를 다시 ready state 상태로 보내고 대기시키는 과정이다.
입출력 발생(Block)
지정된 시간을 초과하기 전에 입출력이나 기타 사건이 발생하면 CPU를 스스로 반납하고 입출력이 될 때까지 대기 상태로 전이된다.
깨움(wake-up)
입출력 종료 시 대기 상태의 프로세스에게 입출력 사실을 wait & signal 등에 의해 알려주고, 준비 상태로 전이됨.
RS-232
PC와 음향 커플러, 모뎀 등을 접속하는 직렬 방식의 인터페이스
HDLC
High-level Data Link Protocol, 다중 방식의 통신에서 동기식 비트 중심의 데이터 링크 프로토콜
PPP
Point-to-Point Protocol, 두 통신 노드 간의 직접적인 연결을 위해 일반적으로 사용되는 데이터 링크 프로토콜
프레임 릴레이
데이터 프레임들의 중계 기능과, 다중화 기능만 수행하여 처리 속도와 전송 지연을 향상 시킴
ATM
정보 전달의 기본단위를 53 바이트 ‘셀 단위’로 전달하는 비동기식 시분할 다중화 방식의 패킷형 전송기술
Switch
허브의 단점을 개선하여, 출발지로 들어온 frame을 목적지 MAC 주소 기반으로 빠르게 전송, 전송방식은:
- cut-through
- store-and-forward
- Fragment Free
가 있다.
Bridge
두 개의 근거리 통신망(LAN)을 연결해주는 통신망
IP
데이터를 패킷 단위로 분할하여, 목적지 주소(IP 주소)를 기반으로 전송 경로를 결정하는 프로토콜
ARP
IP 네트워크 상에서 IP 주소를 MAC 주소로 변환하는 프로토콜
RARP
IP 호스트가 자신의 물리 네트워크 주소(MAC)은 알지만 IP를 모를때 서버로부터 IP주소를 요청하기 위해 사용
ICMP
IP에서 전송 오류 발생 시, 오류 정보를 전송하는 목적으로 사용되는 프로토콜이며 메시지 형식은 8 byte 헤더와 가변 길이의 데이터 영역으로 분리한다. ping 명령어가 대표적으로 ICMP 가 사용됨
IGMP
인터넷 그룹 관리 프로토콜로 멀티캐스팅 그룹을 구성할 때 사용, IGMP 에는 그룹가입, 멤버십감시, 멤버십응답, 멤버십탈퇴가 있어서 그룹을 관리하고 구성하는데 용이하다. 화상회의나 IPTV에서 사용
Router
서로 다른 네트워크 대역에 있는 호스트들 상호 간에 통신이 가능하도록 패킷 위치를 추출해 최적의 경로를 계산하여(라우팅 프로토콜 사용) 경로를 따라 데이터 패킷을 다음 라우터로 전송
L3 Switch
IP 레이어에서 스위칭을 통해 외부로 전송, L2 기능 + 경로 제어 기능 + 고속 라우팅 기능 수행
TCP
데이터나 패킷을 세그먼트로 분리시켜 근거리 통신망에서 인트라넷, 인터넷에 연결된 단말에서 옥텟(1byte)을 안정적으로, 순서대로, 에러 없이 교환할 수 있게 해주는 프로토콜
UDP
비연결성이며 순서화되지 않은 데이터 그램(UDP에서 PDU만 이렇게 유독 부름)을 제공
L4 Switch
4계층에서 네트워크 단위들을 연결하는 통신 장비이며, TCP/UDP 등 스위칭을 수행한다. TCP 에도 여러 프로토콜, UDP 에도 여러 프로토콜이 있는데, FTP, HTTP 등의 프로토콜을 구분하여 스위칭을 하는 Load Balancing 이 가능하다.
NetBIOS
7계층에게 API를 제공하여 통신수행
⭐️RPC
원격 프로시저라고 불리고, 다른 주소 공간에서 함수나 프로시저를 실행할 수 있는 프로세스 간의 통신
HTTP
80번 포트 사용, 하이퍼 텍스트를 빠르게 교환
FTP
21번 포트 사용, TCP/IP 프로토콜을 가지고 서버와 클라이언트 사이의 파일 전송 담당
SMTP
TCP 포트번호 25를 사용해서 이메일을 보내기 위해 사용
POP3
110번 포트를 사용, 원격 서버로 부터 이메일을 가져오는 데 사용
IMAP
143번 포트 사용, TCP/IP 연결을 통해 이메일을 가져오는데 사용
Telnet
인터넷이나 로컬 영역에서 네트워크 연결에 사용되는 네트워크 프로토콜
SSH
22번의 포트를 사용하여 인증, 암호화, 무결성을 제공하여 클라이언트 공개키를 서버에 등록만 하면, 데이터를 암호화하여 컴퓨터 간의 원격 명령 실행, 쉘 서비스를 수앻할 수 있음
SNMP
161번의 포트를 사용하고, TCP/IP 네트워크 관리 프로토콜이다. 라우터나 허브에서 정보를 수집하고 관리하는 프로토콜이다.