
📂 목차
📚 본문
JPA 심화
JPA 는 객체지향적인 데이터 접근이라는 모토를 가지고 만들어진 관계형 데이터베이스 패러다임을 객체지향적으로 바꿔서 접근하는 기술이자 라이브러리이다.
JDBC 와는 다르게 작동하고, 이후에 실무에서도 자주 사용하니 매우 자세히 들여다 볼 것이다.
ORM
객체 지향적으로 보기 위해 데이터 접근 로직을 SQL 에서 분리시키고 비즈니스 로직에만 집중할 수 있도록 지원하기 위해 ORM(Object-Relational Mapping) 이라는 개념을 통해 객체와 테이블을 자동으로 매핑한다.
이러한 개념이 필요한 이유는 다음과 같다. SQL을 직접 작성할 때는 다음과 같은 반복 작업이 필연적으로 발생한다.
문제점
- 자바 상의 객체를 테이블의 row 와 매핑시키기 위한 데이터 변환이 필요
- SQL 문자열을 직접 작성 및 유지보수 하는 것은 굉장히 보일러 플레이트 코드
- DBMS 에 의존하게 되는 쿼리 처리
- 스키마 변경 시 모든 SQL 코드를 수정해야 하고, 이는 곧 JAVA 내부 코드를 수정해야 하는 것과 동일
나무 위키 참조
이러한 이유 때문에 1차적인 수정 이후에도 n차 수정이 필요하게 되는 상황이 발생하며, 매번 유사 코드를 일일히 입력하는 것은 굉장히 노동 집약적인 일이다. JPA 는 이름에 걸맞게 Persistence 라는 논리화된 저장공간을 제공함으로써 개발자에게 위 문제들을 해결 할 편리한 기능들을 제공한다.
JPA 주요 Class
+----------------------------------+
| javax.persistence |
+----------------------------------+
┌──────────────────────────────┐
│ Persistence │ ← JPA 진입점 (static 클래스)
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ EntityManagerFactory │ ← EM 생성 팩토리 (Thread-safe)
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ EntityManager │ ← 영속성 컨텍스트 단위 관리 객체
└──────────────────────────────┘
│ ▲ ▲
│ │ │
│ │ │
▼ │ ▼
┌────────────────────┐ ┌────────────────────┐
│ EntityTransaction │ │ Query │
└────────────────────┘ └────────────────────┘
│ │
▼ ▼
begin(), commit(), rollback() getResultList(), getSingleResult()Persistence정적 클래스:EntityManagerFactory를 생성하는 진입점createEntityManagerFactory(String persistenceUnitName): 내부적으로META-INF/persistence.xml을 읽어 설정 정보를 로드하는 역할을 한다.
EntityManagerFactory인터페이스: EntityManager 인스턴스를 생성하는 팩토리(Thread-safety)createEntityManger()close()- 싱글톤으로 사용해야 한다.
EntityManager인터페이스: 엔티티의 생명주기와 영속성 컨텍스트를 관리하는 핵심 인터페이스persist(),find(),merge(),remove()- 트랜잭션 제어:
EntityManager getTransaction() JPQL실행:createQuery()SQL실행:createNativeQuery()- 쓰레드 안전하지 않기 때문에 한 번 트랜잭션이 실행될 때 동안만 생성되고 사라진다.
- 영속성 컨텍스트 관리를 담당한다.
AutoClosable을 확장하여 제공하기 때문에 자원을 닫아주는 것이 필요
EntityTransaction인터페이스: 트랜잭션을 수동으로 제어할 수 있는 인터페이스begin(),commit(),rollback(),isActive()
Query인터페이스:JPQL또는 네이티브 SQL 을 실행하는 객체setParameter(String name, Object value)setResultList(), getSingleResult()
JPA 활용
순수 JPA 를 쓰기 위해 다음을 추가한다.
implementation 'org.hibernate:hibernate-core:6.4.4.Final'
implementation 'jakarta.persistence:jakarta.persistence-api:3.1.0'JPA 표준 인터페이스는 jakarta 로, 구현체는 hibernate-core 로 들고온다. DB 드라이버는 각자 맞게 들고오자(필자는 mysql).
Hibernate 설정 파일
src/main/resources/META-INF/persistence.xml 를 통해 생성할 EntityManagerPersistence 를 설정해줘야 한다(위 Persistence 정적 클래스 참고).
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="examplePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>com.example.Member</class>
<properties>
<!-- JDBC 설정 -->
<property name="jakarta.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="jakarta.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/exampledb"/>
<property name="jakarta.persistence.jdbc.user" value="{이름}"/>
<property name="jakarta.persistence.jdbc.password" value="{비밀번호}"/>
<!-- hibernate 설정 -->
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>persistence 태그 안에 persistence-unit 이 와야 하며 각 persistence-unit 은 persistence 설정 파일 하나를 의미하는 듯하다. 여기 안에 해당 persistence-unit 이 관리 할 class 태그들을 넣어준다.
transaction-type 옵션: JTA 대신 트랜잭션을 자바 애플리케이션에서 관리한다는 것을 의미
provider 태그: JPA 프로바이더로 Hibernate Core 의org.hibernate.jpa.HibernatePersistenceProvider를 사용
properties 로 jdbc 와 hibernate 구현체에게 인자를 전달할 수 있다.
dialect: 다양한 파생된 SQL 들중 어떤 것을 쓸지 정하는 태그hbm2ddl.autocreate: DB 를 데이터 정의어를 코드 기준으로 새로 생성update: 이미 생성되어져 있는 DB 와 코드가 서로 다르다면 코드 기준으로 업데이트create-update: 어플리케이션 실행 시 코드 기준으로 테이블을 생성하고, 종료 시점에 모두 삭제validate: Java 코드와 DB 스키마가 일치하는지 검증만 수행하고, 수정은 하지 않는 설정none: DDL 자동 생성 기능을 사용하지 않음
show_sql: JPA(Hibernate) 가 실행하는 SQL 쿼리를 콘솔에 출력하도록 설정. SQL이 실제로 어떤 식으로 수행되는지 확인할 때 유용함, 보통 개발 단계에서 사용format_sql: 위 sql 을 보여줄 때, indent 시켜 보여줄지 아닐지 정하는거
@Entity
위 Persistence 가 관리할 클래스로 com.example.Member 를 정의했다. 위 경로대로 클래스 파일을 생성하자.
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
@Entity
public class Member {
@Id
private Long id;
}@Entity 는 JPA 가 관리할 데이터라는 것을 명시해주고, 데이터를 관리하려면 데이터의 구분 기준을 @Id 로 정의해줘야 한다. 따라서 기본적으로 위 구성을 따라야 한다.
/**
* (Optional) The entity name. Defaults to the unqualified
* name of the entity class. This name is used to refer to the
* entity in queries. The name must not be a reserved literal
* in the Jakarta Persistence query language.
*/
String name() default "";주석에 따르면, 해당 이름은 나중에 쿼리에 쓰일 이름이며, 이는 딱히 지정하지 않아도 내부적으로 Member 라는 것으로 query langugage 에 쓰일 예정이다. 이제 이 엔티티를 관리하는 Persistence Context 를 생성하기 위해 Entity Manager 를 생성하고, Entity Manager 를 생성하기 위해 Entity Manager Factory 를 생성해야 한다.
public class Application {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("examplePU");
EntityManager em = emf.createEntityManager();
}
}실행하면 다음 테이블이 생성됨을 볼 수 있다.

JPA 는 내부적으로 비어있는 생성자를 통해 먼저 객체를 생성하고 그 이후에 값을 세팅해주게 된다. 따라서 빈 생성자는 필수이다. 또 여기서 @Id 를 꼭 넣어야 하는 이유는 객체를 구분할 명분이 필요해서 이다. 이를 좀 더 자세히 보자.
엔티티 구분 기준
A persistence context is a set of entity instances in which for any given persistent entity identity (defined by an entity type and primary key) there is at most one entity instance
공식 문서에 따르면, entity type 과 primary key 를 기준으로 정의되는 존재성이 바로 엔티티이다. 이때 테이블은 id 를 키로 하고, id 를 통해 객체를 구분하게 된다.
테이블 명 바꾸기
생성되는 Member 테이블은 클래스 명을 따라가게 되며 명시적으로 자동 생성되는 테이블 명을 지정시켜주려면 다음 어노테이션을 입력한다.
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
@Entity
@Table(name = "members")
public class Member {
@Id
private Long id;
}실행 시 다음과 같이 생성되어 있음을 볼 수 있다.
이제 이 엔티티가 어떻게 생성되고 삭제되기 까지의 생명주기를 보자.
Entity 상태 다이어그램
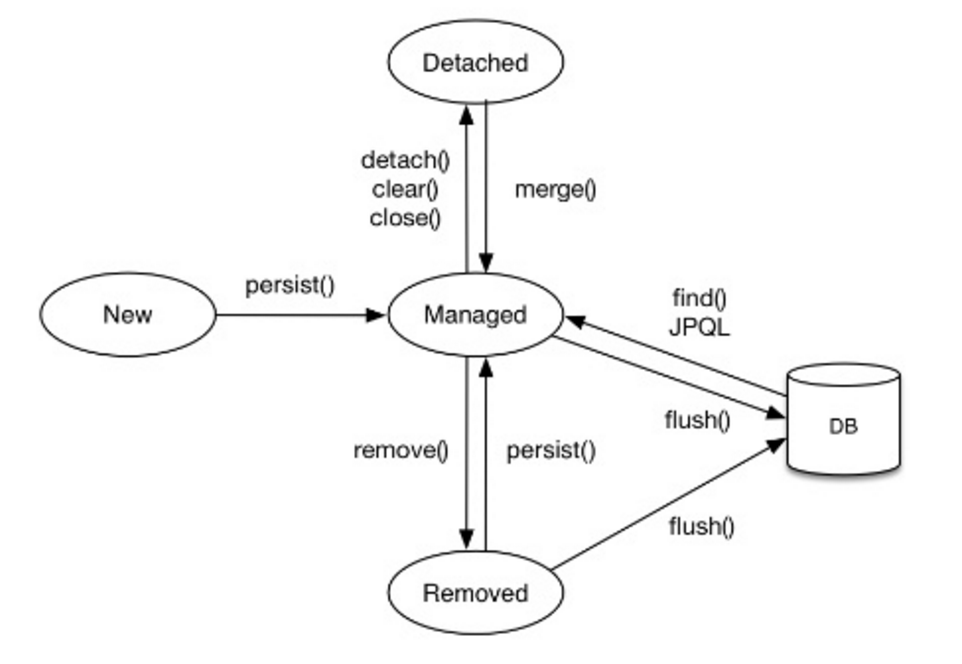
- New: 객체 생성 상태
- Managed: 영속화 상태
- Removed: 삭제예정 상태
- Detached: 비영속화 상태
엔티티는 위와 같은 생명주기를 가진다. 기본적으로 영속화 된 이후에서야 다른 Removed, Detached 로 갈 수 있다.
New 상태
public class Application {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("examplePU");
EntityManager em = emf.createEntityManager();
// New 상태
Member member = new Member();
}
}New 상태
public class Application {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("examplePU");
EntityManager em = emf.createEntityManager();
// New 상태
Member member = new Member();
}
}Managed 상태
public class Application {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("examplePU");
EntityManager em = emf.createEntityManager();
Member member = new Member();
// 영속화 상태
em.persist(member);
}
}Detached 상태
public class Application {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("examplePU");
EntityManager em = emf.createEntityManager();
Member member = new Member();
em.persist(member);
em.detach(member);
}
}Removed 상태
public class Application {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("examplePU");
EntityManager em = emf.createEntityManager();
Member member = new Member();
em.persist(member);
em.remove(member);
}
}위 코드들을 실행시키면 아직 persistence context 에만 올라갈 뿐, Id 를 생성시켜주지 않아서 푸쉬까지는 못한다(커밋하면 org.hibernate.id.IdentifierGenerationException 에러 뜬다..). 따라서 DB 자체에 자동으로 ID 를 생성시켜주는 AUTO_INCREMENT 를 사용하도록 어노테이션을 붙여주어 아이디를 생성시켜주고 커밋을 해줘야 한다.
GeneratedValue
자동으로 생성해주는 @GeneratedValue 어노테이션을 통해 영속 컨텍스트에 진입하는 객체에 대해 Id 값이 null 이면 아이디를 자동 생성시켜주어서 영속성 컨텍스트에 들여오도록 할 수 있다. 애초에 Id 가 null 이면 영속성 컨텍스트에 들어올 수 없다.
@Entity
@Table(name = "members")
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
public Member() { }
public Member(String name) {
this.name = name;
}
}위와 같이 입력해준다. 안에 들어갈 자동 생성 전략은 다음 옵션들이 있다.
GenerationType.IDENTITY: 엔티티 기본 키를 DB의 identity 컬럼을 사용하여PersistenceProvider가 할당해야 함을 명시GenerationType.SEQUENCE: 엔티티 기본 키를 DB의SEQUENCE형을 사용하여PersistenceProvider가 할당해야 함을 명시GenerationType.UUID: 엔티티 기본 키를 RFC 4122 표준의 UUID 를 생성하여PersistenceProvider가 할당해야 함을 명시GenerationType.TABLE: 엔티티 기본 키를PersistenceProvider가 기본 DB 테이블을 사용하여 할당, 실제 DB 안에 별도의 시퀀스 테이블을 만들어서 키 값을 저장하고 조회하기 때문에 DB 종류에 상관 없이 시퀀스 역할 테이블을 만들어서 키 값을 저장GenerationType.AUTO: 위 4개 옵션 중 알아서 할당
아이디를 생성시켜줬다면 다음을 실행시켜서 푸시할 수 있다.
EntityManager em = EMF.createEntityManager();
Member member = new Member();
em.getTransaction().begin();
em.persist(member);
em.getTransaction().commit();EntityTransaction
위에서 getTransaction() 이라는 메서드가 EntityTransaction() 을 반환한다고 이 포스팅 앞부분에서 얘기했다. 이 클래스는 오직 transaction-type 설정 값이 RESOURCE_LOCAL 일때 사용된다.
주요 메서드
begin()– 트랜잭션 시작- 이미 활성화 상태면
IllegalStateException발생
- 이미 활성화 상태면
commit()– 트랜잭션 커밋, DB 반영- 비활성 상태면
IllegalStateException - 실패 시 RollbackException
- 비활성 상태면
rollback()– 트랜잭션 롤백- 비활성 상태면
IllegalStateException - 예기치 않은 오류 발생 시 PersistenceException
- 비활성 상태면
setRollbackOnly()– 트랜잭션을 롤백만 가능하도록 표시- 비활성 상태면
IllegalStateException
- 비활성 상태면
getRollbackOnly()– 롤백 표시 여부 확인isActive()– 트랜잭션 진행 여부 확인
하나의 커밋 단위, 스냅샷 단위를 구분지을 수 있는 트랜잭션 개념을 제공한다. 따라서 위 코드를 좀 더 보기 좋고, 메모리를 고려한 다음과 같이 수정한다.
EntityManager em = EMF.createEntityManager();
Member member = new Member("홍길동");
em.getTransaction().begin();
try {
em.persist(member);
em.getTransaction().commit();
} catch (Exception e) {
if (em.getTransaction().isActive())
em.getTransaction().rollback();
throw e;
} finally {
em.close();
}이제 DB에 record 가 추가되어 있음을 볼 수 있다.
Entity 동일성 vs 동등성
동일성은 메모리 상에서 같은 객체 인스턴스인지를 비교한다.
동일성
Member member1 = new Member("홍길동");
Member member2 = member1;동등성을 보자. 동등성은 엔티티의 내부적인 필드 값들에 대해 같음에 대한 논리적인 비교를 통하여 같은 엔티티인지 비교를 한다. equals() 가 동등성의 예시이다.
이때 JPA 에서의 영속화 컨텍스트 내는 @Id 기준 동등성 비교를 하며, 컬렉션에서는 hashCode() + equals() 기준 동등성 비교를 한다. 따라서 Id 만 잘생성시켜줬다면 알아서 영속화 컨텍스트에 들어가는 엔티티가 같은지 판별해준다. 하지만 이는 다음과 같은 상황을 유발한다.
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
public Member() {}
public Member(String name) { this.name = name; }
// ID 기준으로만 즉, persistence context 내에서만 구분
// equals/hashCode 미구현
}
// Main.class
em.getTransaction().begin();
// New 객체 생성 후 persist
Member m1 = new Member("홍길동");
em.persist(m1);
em.getTransaction().commit();
// m1은 이제 Managed 상태로 ID가 부여됨
System.out.println("m1 ID: " + m1.getId()); // e.g. 1L
// Detached 상태에서 객체 수정
em.detach(m1);
Member m2 = new Member("홍길동"); // 새로운 객체, ID 없음
m2.setId(m1.getId()); // 같은 ID를 강제로 세팅
// 컬렉션에 넣기
Set<Member> members = new HashSet<>();
members.add(m1);
members.add(m2); // equals/hashCode가 없으면 중복 판단 실패 → 두 객체 모두 추가
System.out.println("Set 크기: " + members.size()); // 출력: 2 (중복 있음)
// 비정상적위와 같은 오류 때문에 equals, hashCode 의 구현이 Id 를 기준으로 하도록 구현해야 한다.
// equals 메서드: id 기반 비교
@Override
public boolean equals(Object o) {
if (this == o) return true; // 1. 같은 참조면 true
if (o == null || getClass() != o.getClass()) return false; // 2. null 또는 다른 클래스면 false
Member member = (Member) o;
return id != null && id.equals(member.id); // 3. id가 있고 같으면 true
}
// hashCode 메서드: id 기반
@Override
public int hashCode() {
return id != null ? id.hashCode() : 0; // id가 없으면 0 반환
}하지만 이 또한 다음 상황에 대처를 못한다.
Set<Member> members = new HashSet<>();
members.add(member1);
em.persist(member1); // id 할당
// HashSet에서 hashCode 변경으로 member1을 찾을 수 없음따라서 JPA 에 들어가기전 무조건 value 가 있는 값에 대한 equals() 와 hashCode() 를 구현하는 것을 실무에서는 사용하며, 이를 candidate key(후보 키) 로 선정될 수 있는 값을 고르게 된다(실무에서는 비즈니스 키라고 하는 듯하다). 따라서 equals() + hashCode() 를 id 기준으로 규칙에 맞게 설정해줘야 한다.
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Member member = (Member) o;
return phoneNumber != null && phoneNumber.equals(member.phoneNumber);
}
@Override
public int hashCode() {
return phoneNumber != null ? phoneNumber.hashCode() : 0;
}위에서는 phoneNumber 을 비즈니스 키로 보고 동등성 구현을 한다. 이것만 설정해주면 되는게 아니라 entity 내부에서 phoneNumber 을 비즈니스 키로 한다고 기준을 삼았다면, 엔티티 생명주기 전 구간에서 항상 not null 임을 보장해주어야 한다.
기준으로 삼은 키는 다음 규칙을 통해 동등성 구현을 해주어야 한다.
엔티티 동등성 구현 규칙
- 식별자(id) 기반 비교: 데이터베이스 레코드를 대표하는 id로 비교
- 일관성 유지:
equals()가 true면hashCode()도 같은 값 반환 null처리: 비영속 엔티티는 id 가null일 수 있으므로null처리 필수- 그래서 비즈니스 키로 우회
- 복합 키: 키가 여러 필드로 구성되면 모든 필드로 비교
@Column
JPA(Entity 클래스의 필드) 와 데이터베이스의 컬럼(column) 을 매핑할 때 사용하는 애너테이션이다.
속성
name: 컬럼의 이름, 기본값은 해당 변수명으로 필드명이 DDL 로 선언되게 된다. 아래와 같이 camel 표기법을 snake 로 바꿔줄 수 있다.
@Column(name = "phone_number")
private String phoneNumber;unique: @UniqueConstraint 애너테이션의 또 다른 사용으로 유일 제약 조건이 단일 컬럼에만 적용될 때 쓰면 된다. 기본값은 false 이다.nullable: 데이터베이스의 컬럼이 NULL 을 허용하는지 여부, 기본 값은 true 라서 null 이 들어갈 수 있도록 되어 있다.insertable: PersistenceProvider 가 생성하는 SQLINSERT문에 이 컬럼이 포함될지의 여부이다. 만약 false 라면 insert 가 가능하지 않은 필드며, 기본 값은 true 이다.updatable: PersistenceProvider 가 생성하는 SQLUPDATE문에 ~ 이하 생략columnDefinition: DDL 문을 생성할 때, 칼럼의 타입을 그대로 사용하도록 강제하는 옵션이다.- 예:
@Column(columnDefinition = "VARCHAR(32) DEFAULT 'A'")→ 생성되는 DDL에VARCHAR(32) DEFAULT 'A'가 그대로 들어감 - NOT NULL 도 넣어도 되지만, nullable 에 쓰는게 가독성이 더 좋을 듯하다.
- 예:
table: 거의 사용되지 않음, 특정 엔티티가 여러 테이블에 매핑이 될 때, 해당 컬럼이 어느 테이블에 속하는지 지정하기 위해 존재함. 보통SecondaryTable이나SecondaryTables와 같은 어노테이션과 함께 엔티티가 여러 테이블에서 사용될 때 사용하는데, 다음 예제를 보면 이해가 될 것이다.
@Entity
@Table(name = "members")
@SecondaryTable(name = "member_details")
public class Member {
@Id
private Long id;
@Column(name = "username")
private String username; // 기본 테이블 members
@Column(table = "member_details", name = "address")
private String address; // 보조 테이블 member_details
@Column(table = "member_details", name = "phone_number")
private String phoneNumber; // 보조 테이블 member_details
}address, phoneNumber 는 member_details 라는 보조 테이블에 저장되고, JPA 가 내부적으로 두 테이블을 ID 기준으로 조인해서 관리하게 된다.
하지만 이는 left join 을 사용하기 때문에 성능상 안좋다. 따라서 자주 사용하지 않는 세부 정보를 분리시켜야 할 때만 사용하는 것이 좋다.
length: DDL 테이블을 생성할 때,VARCHAR형태의 컬럼을 만들기 위해 사용된다.length = 100이라면VARCHAR(100)에 매핑된다.precision: 숫자(DECIMAL, NUMERIC 등) 타입의 전체 자릿수(정수부 + 소수부)를 지정하는 옵션이다, scale 과 같이 써야 한다. 만약 scale 을 안쓰면 DB 마다 이를 달리 해석하여 타입을 정하게 된다.scale: 소수점 이하의 자릿수를 지정하는 옵션, precision 과 같이 써야 한다. 만약 scale 만 있게 되면 오류가 발생 할 수도 있고 아닐 수도 있다. 그냥 같이 쓰자.
@Enumerated
Enum 타입 매핑을 할 수 있다.
public @interface Enumerated {
/** (Optional) The type used in mapping an enum type. */
EnumType value() default ORDINAL;
}EnumType.ORDINAL: DB 에 Enum 순서(0, 1, 2, …) 로 저장하도록 한다.EnumType.STRING: DB 에 Enum 이름(String) 으로 저장하도록 한다.
public enum MemberStatus {
ACTIVE,
INACTIVE,
SUSPENDED
}ORDINAL 규칙을 사용하여 저장할 것이라면, 순서가 바뀌면 모든 데이터가 서로 매핑(순서)이 이상하게 되기 때문에 STRING 을 하는게 좋다. 이때 STRING 으로 하면 자동으로 VARCHAR 타입이 됨을 알고 있자.
@Temporal
Java 의 Date/Calendar 타입에는 날짜 + 시간 정보가 모두 들어있는데, DB 에는 DATE, TIME, TIMESTAMP 등의 여러 타입으로 나뉘어 저장해야할 수도 있다. 이들에게 매핑시키기 위해 Temporal 어노테이션을 제공하며, 필드에 적용시킬 수 있다.
TemporalType.Date: 날짜만 저장 (DATEyyyy-MM-dd)TemporalType.TIME: 시간만 저장 (TIMEHH:mm:ss)TemporalType.TIMESTAMP: 날짜 + 시간 모두 저장 (yyyy-MM-dd HH:mm:ss)
Temporal은 자동 생성이 아니다. 그냥 매핑만 하는것이다. 생성은 따로 해줘야 한다..
@Lob
문자열 CLOB, 바이너리 BLOB 와 같은 데이터를 정의하고 싶을때 필드에 붙이는 어노테이션이다. 굉장히 큰 데이터를 저장하기 위한 어노테이션이기 때문에 기본적으로 조회할 때 Lazy 로딩을 써야 한다.
@Lob
@Basic(fetch = FetchType.LAZY)
private byte[] imageData;
@Basic은fetch,optional속성만 가지고, 어렵지 않기에 쓰게 될 경우에는 코드 내부를 즉석으로 파헤쳐서 쓰는게 좋다, 기본 값은 각각FetchType.EAGER,true이다.
@PrePersist 와 @PostPersist
@PrePersist 는 우선 메서드에 적용하는 JPA 표준 어노테이션이며, 이 어노테이션이 붙은 메서드는 JPA 엔티티 내부에서 선언되고, JPA 엔티티를 영속화 후 커밋하기 직전에 호출하게 된다. @PostPersist 는 당연하게도 SQL 실행 후의 실행이다(INSERT 문 실행 직전/직후).
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, updatable = false)
private LocalDateTime createdAt;
@PrePersist
protected void onCreate() {
System.out.println("PrePersist 호출!");
createdAt = LocalDateTime.now();
}
@PostPersist
protected void afterInsert() {
System.out.println("PostPersist 호출!");
}
}유사하게
@PreUpdate,@PostUpdate,@PreRemove,@PostRemove도 있다.@PostLoad는 엔티티 SELECT 직후에 수행된다.
JPA 엔티티 매핑
테이블에는 JOIN 과 같은 연산을 통해 테이블에 분산된 필드들을 합쳐서 조회할 수 있는 기능을 제공한다. 이를 JPA 에서도 할 수 있다. 여기서는 소유주(Foreign Key 를 가지는 엔티티)가 누구냐가 중요하며, 이를 기준으로 쓰는 애너테이션이 달라진다.
@OneToOne
단방향 관계를 정의하고 싶을때 사용한다.
@Entity
public class Member {
@Id
private Long id;
@OneToOne
@JoinColumn(name = "locker_id") // FK 컬럼 지정
private Locker locker;
}@JoinColumn 은 외래 키 컬럼을 정의하는 어노테이션이며, 실제 locker_id 라는 필드명의 열이 생성되며, 이 말은 Member 이 해당 관계의 소유주라는 것이다. @JoinColumn 은 이러한 @~To~ 의 어노테이션과 함께 써야하는 어노테이션이다.
@JoinColumn 이 붙여진 필드는 타입을 통해서 저장할 엔티티를 식별하고, 해당 엔티티의 식별자(@Id) 정보를 가져와 @JoinColumn 안의 name 속성을 통해서 열을 정의하게 된다. JoinColumn 어노테이션은 name 속성외에 다양한 속성들을 넣을 수 있다:
JoinColumn 속성
referencedColumnName: 참조할 컬럼 지정, 기본적으로@Id가 붙은 필드 지정nullable: FK 컬럼이 NULL 을 허용할지의 여부이다, 기본 값은 true 이다.insertable / updatable: 설명 생략, 기본 값은 둘 다 true 이다.unique: FK 컬럼의 유일 여부(OneToOne에서는 이 속성이 반드시true여야 한다.), 기본값은 false 이다.
UNIQUE제약은NULL끼리의 중복은 허용하게 된다.
OneToOne 속성
-
mappedBy: 양방향 연관관계를 설정할 때 핵심적으로 사용하는 속성인데, 연관관계의 주인이 아닌 쪽에서 사용한다. 즉, FK 를 안가지고 있는 쪽에서 사용하며 속성 값으로는 주인이 가진 필드 이름(변수 명)을 지정하게 된다. fetch: 연관 엔티티의 로딩 방식을 지정한다.FetchType.EAGER가 기본 값이다.FetchType.EAGER: 해당 엔티티를 가져올 때, 연관 엔티티도 기본적으로 다 가져옴FetchType.LAZY: 기본적으로 프록시 객체를 생성하여 미리 채워놨다가, 로직에서 필요한 일이 생길때 그제서야 SQL 문을 던져 해당 프록시 객체를 대체하여 채우게 된다(메모리 최적화).
cascade: 연관 엔티티에 대한 작업을 전파할지 안할지이다. 이는 이전에 배웠던 JS 에서의 클릭 이벤트를 하위 자식에게도 전파할지 아니면 상위 부모에게도 전파할지 아닐지의 개념과 같다.CascadeType.PERSIST: 해당 엔티티를Persistence Context에 올릴 때 연관 엔티티도 자동으로Persistence Context에 올림CascadeType.MERGE: 해당 엔티티를 병합할 때(비영속-> 영속) 연관 엔티티도 병합CascadeType.REMOVE: 해당 엔티티를 삭제할 때 연관 엔티티도 자동 삭제CascadeType.REFRESH: 엔티티를 DB 에서 다시 읽어들일 때, 연관 엔티티도 다시 읽어들임CascadeType.DETACH: 영속 -> 비영속 이하 설명 동일CascadeType.ALL: 위 옵션들 다 때려 넣은 속성
-
orphanRemoval: 컬렉션이나 단일 엔티티를 소유하는 관계(owner) 쪽에서 사용해야 의미가 있으며, 해당 소유자가 삭제되면 그 하위 관련 엔티티도 자동 삭제가 된다. 기본값은false이다. optional:null값 허용 여부 기본은true
위처럼 애너테이션을 필드에 넣었다면 연관된 다른 객체에서는 굳이 아무것도 안해줘도 된다. 하지만 서로간의 데이터를 서로 가지게 하고 싶게 하려면 다음과 같이 구성해야 한다(양방향 소유).
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToOne(mappedBy = "member") // Locker가 FK 소유하기에 mappedBy 는 소유주 쪽의 변수명을 String 리터럴로 선언
private Locker locker;
}
@Entity
public class Locker {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String code;
@OneToOne
@JoinColumn(name = "member_id", unique = true) // FK 소유, UNIQUE 제약 조건 명시
private Member member;
}DDL 은 다음과 같이 된다.
CREATE TABLE member (
id BIGINT PRIMARY KEY,
name VARCHAR(255)
);
CREATE TABLE locker (
id BIGINT PRIMARY KEY,
code VARCHAR(255),
member_id BIGINT UNIQUE, -- 1:1 관계이므로 UNIQUE 제약
CONSTRAINT fk_locker_member FOREIGN KEY (member_id)
REFERENCES member(id)
);OneToOne 에서의 FetchType.LAZY 로딩의 문제점
성능 최적화를 위해 이때 FetchType.LAZY 로딩을 쓰고 싶을 수 있는데, Locker 는 FK 를 가지고 있기 때문에 owner 이며, Member 는 FK 가 없는 mappedBy 로 종속되고 있는 필드이다. 이때 Member 쪽의 필드에서 FetchType.LAZY 를 적용했다고 쳤을 때, Member 를 조회할 때는 JPA 가 프록시 객체를 만들어서 실제 객체는 필요할 때만 가져오게 될 것이다.
근데 여기서 프록시 객체가 정상 동작을 하려면 FK 값이나 식별자를 미리 알아야 한다. 근데 DB 스키마에는 member 테이블에 FK 가 있지 않고 locker 테이블에 FK 를 소유하도록 소유자를 정했기 때문에 프록시 객체가 잘 동작하지 않게 되어서 결국에는 JPA 가 프록시 객체를 생성 못하고 해당 필드를 채우기 위해 바로 조회하도록 하게 만들게 된다. 이는 Fetch.EAGER 로 동작하게 되는 것과 같은 원리다.
따라서 다음을 통해 해겷한다:
- FK 를 주인 쪽에 뚜기 -> 정상
LAZY ManyToOne+UNIQUE제약 패턴 사용 ->LAZY정상 동작 가능
toString(), JSON 의 재귀적 호출 가능성
OneToOne 에서나 어느 다른 관계에서나 서로 엔티티 내부에 서로의 변수를 가지도록 한다고 해보자. 그렇다면, toString() 으로 출력할 때, JSON 으로 직렬화 할때에서 서로 계속 호출하게 되어서 무한 루프가 발생한다.
이를 방지하기 위해 OneToOne 에서나 OneToMany 에서는 다음 해결책을 쓴다:
- 문자열 출력 문제는
toString()두 엔티티 중 한 쪽에서 내부적으로 해당 필드 제외 - 직렬화 문제는
@JsonIgnore사용 - DTO 로 변환시켜 따로 필드를 선언 후 관리
@ManyToOne, @OneToMany
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// Member → Order (1:N)
@OneToMany(mappedBy = "member", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Order> orders = new ArrayList<>();
// 편의 메서드
public void addOrder(Order order) {
orders.add(order);
order.setMember(this);
}
public void removeOrder(Order order) {
orders.remove(order);
order.setMember(null);
}
}
@Entity
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String orderNumber;
// Order → Member (N:1)
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;
public void setMember(Member member) {
this.member = member;
}
}ManyToOne 과 OneToMany 는 항상 서로 붙어 다니는 것을 기억하자. ()To() 중에 첫번재로 오는 단어의 기준은 항상 해당 엔티티에서 나아가는 대응되는 것으로 생각한다. 따라서 Order 의 다수가 Member 1명으로 가기 때문에 Order 에서는 ManyToOne 을 쓴 것을 볼 수 있다.
나머지는 다 똑같다. JoinColumn 은 소유하는 엔티티 쪽에 선언하고, FK 필드를 생성하게 Member 하나만 가지게 되는 쪽에 당연히 들어가는게 맞다(Member 쪽에 JoinColumn 을 넣었다면 Order 가 여러 개 이기 때문에 이는 한 필드에 여러 엔티티가 들어가게 됨을 의미한다… 모순이며 중간 테이블이 생성되게 될 수도 있다 bad pattern). 또한 mappedBy 는 당연히 FK 에 의해 종속되는 곳 쪽의 엔티티에서 가져야 한다.
EAGER, LAZY 그리고 N+1 문제
이전에 봤듯이 EAGER 는 사용 안하는 편이 좋음을 볼 수 있다. 굳이 사용하지도 않는 필드에 대해 다 가지고 와서는 메모리를 다 잡도록 하기 때문에 기본적으로 실무에서는 LAZY 를 전부 다 쓴다. 또한 EAGER 는 내부적으로 SQL 문이 다음과 같이 매번 바뀐다:
- 부모 엔티티를 조회하고 그 안의 연관 엔티티들도 조회하려고 할 때,
- N+1 SELECT 문제가 발생할 수 있음 (예:
Team조회 후Team내부의Member를 순회하면서 각Member를 별도로 조회)
- N+1 SELECT 문제가 발생할 수 있음 (예:
- 컬렉션 필드가
EAGER일 경우, 내부적으로 SQL이 한 번에 조인되거나 별도SELECT로 조회될 수 있음- FK 컬럼이
nullable = true인 경우,LEFT JOIN이 사용되어 연관 엔티티가 없어도 부모 엔티티는 조회됨 → 카르테시안 곱으로 불필요한 데이터 로딩, 성능 상 안좋음 - FK 컬럼이
nullable = false인 경우,INNER JOIN으로 최적화되어 불필요한 행이 줄어듦 이는 성능 상 좋음
- FK 컬럼이
절대 사용하지 말자.
따라서 LAZY 를 사용하면 되겠지만, LAZY 에서 하나를 들고 오고(Team 을 들고오고 내부적으로 List<Member> 에 프록시 객체들을 넣어놓음) 다시 그 내부 연관 엔티티들을 순회할 때는 당연히 N+1 번 수행하게 된다. 따라서 위 문제들을 전부 해결하지는 못하고 N+1 의 문제만을 여전히 남겨둔다.
이 문제는 비즈니스 로직에서 내부적으로 연관 엔티티를 전부 순회해야하는 로직이 필요할 때 발생하기에 이런 로직이 없다면 그냥
LAZY만 써도 된다. 아래의fetch join은 선택적으로 써야한다.
이를 해결할 수 있는게 바로 fetch join 이다. fetch join 은 sql 문에 직접 있는 기능이며, 이는 inner join 으로 효율적으로 들고오며, eager 에서의 N 번의 select 없이 해당 연관 엔티티들도 전부 영속성 컨텍스트에 올라가게 되며, 내부의 연관 엔티티까지 조회할때 추가적인 SQL 문 없이 컨텍스트에서 사용할 수 있게 된다.
@ManyToMany
다 대 다의 관계는 보통 실무에서는 중간 테이블을 통해 구현된다. 따라서 다 대 다 어노테이션이 있다면 물리적으로 중간에 테이블이 따로 있다고 보면 된다.
중간에 테이블을 따로 두는 이유는 관계형 데이터베이스는 다대다라는 관계를 지원하지 않는다. 컬렉션 필드를 저장할 수 없을 뿐더러 FK 한 개로는 1:N 관계만이 가능하기에, 중간 테이블을 둬서 관리하게 된다.
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany
@JoinTable(
name = "student_course", // 중간 테이블 이름
joinColumns = @JoinColumn(name = "student_id"), // 현재 엔티티 FK
inverseJoinColumns = @JoinColumn(name = "course_id") // 상대 엔티티 FK
)
private List<Course> courses = new ArrayList<>();
}
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
}Student 가 Courses 를 소유하는 예시이다. 두 쪽 다 접근할 수 있게 하려면 다음 코드로 짠다.
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id")
)
private List<Course> courses = new ArrayList<>();
}
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@ManyToMany(mappedBy = "courses")
private List<Student> students = new ArrayList<>();
}JoinTable 에 대해서만 정리하자:
- 다대다(ManyToMany) 관계에서 중간 테이블(join table)을 정의할 때 사용
- 중간 테이블 이름, 외래 키 컬럼 등을 지정 가능
- 단방향/양방향 관계 모두 사용 가능
| 속성 | 설명 | 기본값 |
|---|---|---|
name |
중간 테이블의 이름 지정 | 엔티티 이름 기반 자동 생성 |
joinColumns |
현재 엔티티(FK 소유 엔티티)와 연결되는 컬럼 지정 | 자동 생성 |
inverseJoinColumns |
상대 엔티티와 연결되는 컬럼 지정 | 자동 생성 |
catalog |
테이블이 속하는 DB 카탈로그 이름 | ”” |
schema |
테이블이 속하는 DB 스키마 이름 | ”” |
uniqueConstraints |
중간 테이블의 UNIQUE 제약 조건 지정 |
없음 |
indexes |
중간 테이블에 생성할 인덱스 지정 | 없음 |
Lombok EqualsAndHashCode
위에서 엔티티의 동등성을 구현하는 예제를 보았다. 이를 계속 구현해서 쓰기는 반복되는 보일러플레이트 코드가 있을 수 있어 롬복에서는 EqualsAndHashCode 를 통해 쉽게 equals, hashCode 를 생성할 수 있다.
모든 필드 기준으로 동등성 검증
import lombok.EqualsAndHashCode;
import lombok.Data;
@Data
@EqualsAndHashCode
public class User {
private Long id;
private String name;
private String email;
}특정 필드만 사용
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@Data
public class User {
@EqualsAndHashCode.Include
private Long id;
private String name;
private String email;
}특정 필드만 제와
@EqualsAndHashCode.Exclude
private String tempField; // equals/hashCode에 포함되지 않음EqualsAndHashCode 속성
String[] of:equals(),hashCode()에 어떤 필드만 비교/사용할지 명시String[] exclude: 어떤 필드들을 제외할지 지정boolean callSuper: 슈퍼 클래스의equals/hashCode도 포함CacheStrategy cacheStrategy:hashCode()를 처음 한 번만 계산하고, 그 이후에는 그 결과를 캐싱해서 그대로 가져올 수 있음, 단 해당 객체의 필드가 불변이어야 하며, 불변이 아니라면 캐싱된 값이 잘못된 해시 값으로 남음
용어
JTA
- 자바 표준 트랜잭션 관리 API
- 여러 리소스(DB, 메시지 큐 등)에 걸친 분산 트랜잭션 관리 가능
-
ACID 트랜잭션 보장
- JTA vs RESOURCE_LOCAL
| 구분 | JTA | RESOURCE_LOCAL |
|---|---|---|
| 트랜잭션 관리 | 컨테이너(EJB, Spring) / 애플리케이션 서버 | 애플리케이션 내에서 직접 |
| 지원 범위 | 여러 DB, JMS 등 분산 트랜잭션 | 단일 DB 트랜잭션 |
| 선언 | transaction-type="JTA" |
transaction-type="RESOURCE_LOCAL" |
| 커밋/롤백 | 컨테이너가 관리 | 개발자가 직접 EntityTransaction 사용 |
- JPA에서 활용
persistence.xml에서transaction-type="JTA"설정- 컨테이너가 트랜잭션 관리 →
EntityTransaction사용 불필요 - Spring에서는
@Transactional어노테이션으로 간편하게 트랜잭션 관리 가능
- 핵심 요약
- JTA는 분산 트랜잭션 관리용 표준 API
- 단일 DB만 사용할 경우는 RESOURCE_LOCAL 사용
- 엔터프라이즈 환경에서 여러 리소스를 하나의 트랜잭션으로 묶고 싶을 때 사용
PersistenceProvider
- JPA 구현체를 나타내는 인터페이스
- JPA 표준 인터페이스(
EntityManager,EntityManagerFactory등)를 실제 구현체(Hibernate,EclipseLink등)와 연결 -
Persistence.createEntityManagerFactory()호출 시 내부적으로 사용 - 역할
EntityManagerFactory생성EntityManager생성 시 내부 로직 제공- 트랜잭션 처리, 영속성 컨텍스트 관리, SQL 생성 등 JPA 기능을 구현
- 대표 구현체 예시
- Hibernate:
org.hibernate.jpa.HibernatePersistenceProvider - EclipseLink:
org.eclipse.persistence.jpa.PersistenceProvider
- Hibernate:
- JPA 설정 예시 (
persistence.xml)
<persistence-unit name="examplePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>com.example.Member</class>
<properties>
<!-- JDBC 및 Hibernate 설정 -->
</properties>
</persistence-unit>