
📂 목차
📚 본문
Database
데이터를 체계적으로 저장하고 관리하는 시스템이다.
주로 다루는 데이터들의 특징은 다음과 같다.
DB가 다루는 데이터 3V
- 매우 가치가 높은 데이터
- 상대적으로 큰 규모의 데이터
- 동시에 여러 사용자와 응용 프로그램에서 접근하는 데이터
최근에는 데이터의 특성에서 보다 복잡한 관계나 가변적 구조의 데이터들까지도 포함된다.
DBMS
데이터베이스 관리 시스템은 서로 연관된 데이터의 집합과 그 데이터를 접근하기 위한 프로그램의 집합이다.
목표는 정보를 편리하고 효율적으로 저장하고 검색할 수 있는 방법을 제공하는 것을 목표로 한다.
Abstraction and DB
이러한 데이터베이스 시스템은 다음 특징이 있다.
- 공통된 데이터 구조를 활용해 효율성 확보
- 약하게 구조화된 데이터, 다양한 형식의 데이터도 처리 가능
- 방대한 데이터 집합을 관리하는 대규모, 복잡 소프트웨어 시스템
여기서 다양한 데이터들, 대규모 등 복잡한 어플리케이션이 필요한데 이러한 복잡성을 관리하는 핵심이 추상화이다. 따라서 DB 시스템 내에서 사용자와 개발자에게 데이터 저장, 조직화 등의 방식을 숨김으로써 데이터를 간단히 조작 할 수 있게 한다.
DB 의 변천사
초기 DB 는 백오피스 시스템으로 운영되었지만, 사용자는 인쇄된 보고서나 이벽용 종이 양식을 통해 간접적으로만 상호작용을 했다.
현대에 와서는 DB를 다룰 수 있는 다양한 언어가 나오고, DB 접근의 세부사항은 감추되 다양한 인터페이스와 손 쉬운 인터페이스를 제공하게 되었고, 현재는 2개의 방식을 지원하는데:
-
OLTP: 다수의 사용자가 동시에 DB 를 사용하며 각 사용자는 비교적 소량의 데이터를 조회하거나 작은 단위의 갱신 작업을 수행한다.
-
Data Analytics: 데이터를 처리, 결론을 도출하여 규칙이나 의사결정 절차를 추론한 뒤, 이를 바탕으로 비즈니스 의사결정을 내리는 것
Purpose of DB
시스템은 여러 개의 응용 프로그램을 두어서 파일을 다루게 되는데, 운영체제에는 파일 처리 시스템이 있어 이 안에 다양한 프로그램을 통해 다루게 되는 것이 그 예이다. 하지만 보통 정보를 파일 처리 시스템으로 보관하게 된다면 문제점이 있다.
운영체제의 3V 데이터 처리 문제점
- Data Redundancy and Inconsistency: 여러 프로그래머가 장기간에 걸쳐 파일과 응용 프로그램을 작성하기 때문에 파일 구조가 제각각이며, 프로그램 또한 서로 다른 프로그래밍 언어 혹은 다른 확장자로 작성될 수 있다.
2015-12-29.txt, …, 2020-12-29.json, …
확장자 다름
- Difficulty in Accessing Data: 대학의 한 행정 직원이 특정 우편번호 지역에 사는 학생들의 이름을 알고 싶어한다고 치면, 데이터 처리 부서에 해당 목록을 요청하면 되지만, 원래 시스템 설계자가 이를 염두 안해두고 이런 파일들을 따로 모아놓지 않았다면 일일히 하나하나 다 찾아가면서 해야 한다.
2025/12월/* <- 접근 용이, 2025 년에 접속 횟수 5회 이상 유저 <- 힘듦
- Data Isolation: 파일 여러 개가 흩어져 있으면 파일 형식이 다를 수 있기 때문에 필요한 데이터를 검색하기 위한 새로운 응용 프로그램을 작성하는 것이 어려움
2015-12-29.txt, 2020-12-29.txt
어떤건 ANSI, 어떤건 UTF-8 등
- Integrity Problems: 데이터베이스에 저장된 값은 특정한 일관성 제약 조건을 만족해야 한다. 하지만, 이러한 새로운 제약 조건이 추가될 때, 기존 프로그램을 수정하여 이를 강제하는 것은 어렵다.
2021-12-31 John 100
2011 11 11 🦁 -193.13
위 데이터는 두 형식이 완전 다름.
-
Atomicity Problems: 항상 언급되는 자원 관리에 대한 처리 방식이다. Atomicity 는 원자성이다. 원자는 더이상 쪼개지지 않으며 분리되지 않는다. 그 자체로 하나이며, 만약 어떤 연산을 되돌리고 싶을때 Atomic 한 연산들을 단위로 되돌려야 함을 말한다. 하지만, 운영체제의 파일 처리 시스템은 여러 연산을 한 번에 되돌리고 한 번에 처리하기가 힘들 것이다.
-
Concurrent-Access Anomlies: 시스템의 전반적인 성능과 빠른 응답을 위해 많은 시스템은 여러 사용자가 동시에 데이터를 갱신할 수 있도록 시스템을 운영해야 한다.
위 문제들을 다 해결할 수 있을 때 비로소 DB 라고 할 수 있다.
View of Data
-
Relational Model: 관계형 모델은 데이터를 표현하고, 그 데이터들 간의 관계를 표현하기 위한 테이블 집합을 사용한다.
-
Entity-Relational Model: 개체라 불리는 기본 객체들과, 이 객체들 간의 관계 집합을 사용한다(E-R 다이어그램이다)
-
Semi-structured Data Model: 반구조적 데이터 모델은 동일한 유형의 데이터 항목이더라도 서로 다른 속성 집합을 가질 수 있도록 허용한다. 이는 모든 데이터 항목이 반드시 동일한 속성 집합을 가지지 않아도 된다는 뜻이다(JSON, XML 등이 그 예이다).
-
Object-Based Data Model: 객체 기반 데이터 모델이며, 처음에 객체지향 데이터 모델이라는 별도의 모델 개발로 이어졌지만, 객체 개념이 관계형 데이터베이스에 잘 통합되어 있다.
여기서는 Procedure 를 데이터베이스 내에 저장하고, 시스템 자체에서 실행할 수 있도록 허용하게 된다.
우리가 주로 볼 것은 첫번째이다.
Data Abstraction
시스템이 사용 가능하려면 데이터를 효율적으로 검색할 수 있어야 한다. 이러한 효율성은 데이터베이스 시스템 개발자들이 데이터베이스 내 데이터를 표현하기 위해 복잡한 자료구조를 사용하게 만들었다.
하지만, 많은 사용자들이 컴퓨터 전공자가 아니다. 따라서 데이터 추상화를 통해 복잡성을 감추게 된다.
추상화 수준은 3가지가 있다.
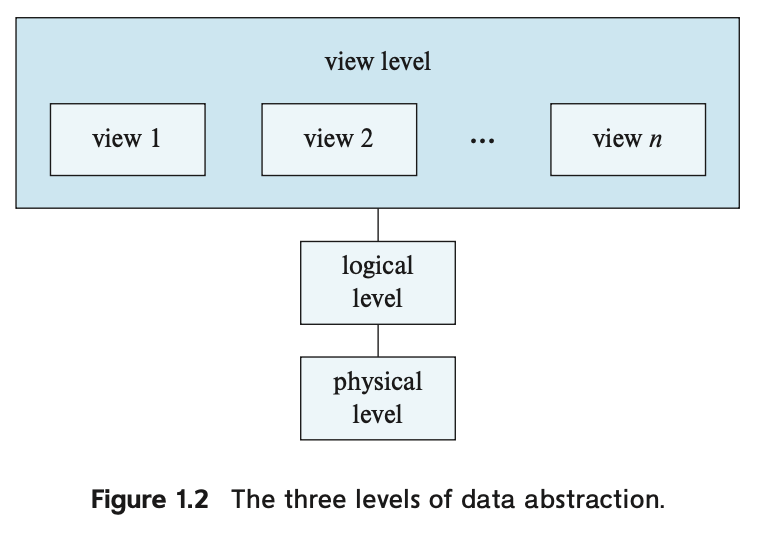
-
Physical Level: 가장 낮은 수준의 추상화로, 데이터가 실제로 어떻게 저장되는지 설명한다, 복잡하고 저수준의 자료구조를 상세히 기술
-
Logical Level: 한 단계 높은 추상화로 DB에 어떤 데이터가 저장되는지와 데이터 간의 관계를 설명, 물론 논리적 수준의 단순한 구조 설계가 실제 물리적 수준의 복잡한 구조의 이해를 수반할 수 있지만, 논리적 수준의 사용자는 이러한 복잡성을 알 필요가 없다.
-
View Level: 가장 높은 추상화로, 전체 데이터베이스의 일부만을 설명한다. 논리적 수준이 비교적 단순한 구조를 사용한다고 해도, 대규모 데이터베이스에 저장되는 정보가 다양하기 때문에 여전히 복잡성이 존재한다.
data type 에 따른 java 에서의 record 정의를 보면 이걸 data abstraction 에 비유할 수 있다.
예시를 보자.
department, with fieldsdept_name,building, andbudget.course, with fieldscourse_id,title,dept_name, andcredits.student, with fieldsID,name,dept_name, andtot_cred.
물리적 수준
department, department, student 는 물리적 수준에서 연속된 바이트 블록으로 표현될 수 있다. 이러한 연속된 바이트 블록으로 표현되어 있다는 것은 프로그래머에게 숨기게 된다.
또한 DBA 는 데이터의 물리적 조직에 관한 일부 세부사항을 인지하고 싶을 수 있다. 이때 테이블을 파일에 저장하는 방법은 여러가지가 있는데
-
테이블을 파일 내 레코드의 연속으로 저장(쉼표, 특수문자, 줄바꿈 등 활용)
-
모든 속성이 고정 길이인 경우, 속성의 길이를 별도로 저장하고, 구분자 생략
-
가변 길이 속성은 길이를 먼저 저장 후 데이터를 저장하는 방식으로 처리
그리고 DB는 인덱스라는 자료구조를 사용하여 레코드를 효율적으로 검색할 수 있도록 지원하며, 이러한 인덱스도 물리적 수준에 포함된다.
물리적 수준 = 바이트 블록 + 저장 구조 + 인덱스
Instances and Schemas
DB 에는 정보가 삽입되고 삭제됨에 따라 시간이 지나면서 변한다.
특정 시점의 데이터베이스에 저장된 정보의 집합을 Instance 라고 한다. 그라고 DB의 전체 설계를 DB Schema 라고 부른다.
스키마와 인스턴스 개념을 프로그래밍 언어에 비유해서 보면 다음과 같다:
- DB Schema 는 프로그램의 변수 선언에 해당, 각 변수들은 특정 시점에 고유한 값을 가짐
- 프로그램 내 변수들의 값은 특정 시점의 DB Instance 에 해당함.
이러한 스키마는 DB 시스템에서의 추상화 수준에 따라 여러 스키마가 존재하게 되며, 물리적 스키마, 논리적 스키마, 뷰 스키마 등이 있다.
Database Languages
DB를 이제 다룰 수 있는 언어를 보자.
- DDL: 데이터 정의어라고 부르며, DB 스키마를 지정한다.
- DML: 데이터 조작어라고 부르며, 조회(query) 와 갱신(update)를 표현할 수 있다.
- DCL: 데이터 제어어라고 부르며, 보통 권한, 보안을 담당하게 된다.
DDL
DDL 은 데이터 추가 속성을 지정하는 데에 사용된다. 이때 우리는 안에 어떻게 정의를 해야하는지 알 필요 없고, DDL 이라는 인터페이스를 통해 명령만 내리면 된다.
여기서 저장되는 값들은 Consistency Constraints 를 만족해야 한다(특정 값은 음수가 안되어야 하고, 자수를 넘기면 안되고 등등). 이러한 제약조건을 지정할 수 있는 기능을 제공하는게 DDL 이다.
일반적으로 제약 조건은 데이터베이스와 관련된 임의 조건(predicate) 일 수 있는데, 임의 조건의 검사는 비용이 많이 들기 때문에 DB 시스템에서는 최소한의 비용으로 검사 가능한 무결성 제약(Integrity Constraints)만 구현하고 우리에게 제공한다.
Domain Constraints
모든 속성에는 가능한 값의 범위가 지정되어야 함의 제약조건이다.
Referential Integrity
특정 속성 집합에 나타난 값이 다른 릴레이션의 특정 속성 집합에도 존재해야 함을 보장하고자 할 때 사용한다.
Authorization
데이터베이스 내 다양한 데이터 값에 대해 사용자가 허용되는 접근 유형을 구분할 수 있다.
- 읽기 권한(read authorziation)
- 삽입 권한(insert authorization)
- 수정 권한(update authorization)
- 삭제 권한(delete authorization)
DDL 문을 처리하는 과정은 다른 프로그래밍 언어와 마찬가지로 출력을 생성한다. 이러한 출력은 보통 Data Dictionary 에 저장되며, 데이터 사전은 Metadata 즉, 데이터에 대한 데이터를 포함하며, 데이터 사전은 특수한 유형의 테이블로 간주되고, 일반 사용자가 접근하거나 수정할 수 없고 오로지 DBMS 자체만 접근 및 갱신 할 수 있다.
SQL DDL
DB Languages 중 하나인 SQL 은 데이터 정의어를 풍부하게 제공하며, 이를 통해 테이블, 데이터 타입 무결성 제약 조건을 정의할 수 있다.
예를들어 다음 department 테이블을 정의할 수 있다.
create table department
(
dept_name char(20),
building char(15),
budget numeric(12,2)
);또한 SQL DDL 은 다양한 유형의 무결성 제약 조건을 지원한다.
기본키, 외래키, NOT NULL 등등
DML
데이터 조작어는 적절한 데이터 모델로 조직된 데이터를 접근하거나 조작할 수 있게 해주는 언어이다.
목적
- Data Retrieval: 데이터 조회
- Data Insertion: 데이터 삽입
- Data Deletion: 데이터 삭제
- Data Modification: 데이터 수정
여기서 DML 은 다시 두 가지 유형으로 나뉘는데
- Procedural DML: 사용자가 필요한 데이터와 그 데이터를 얻는 방법을 지정
- Declarative DML: 사용자가 필요한 데이터만 지정하고, 데이터를 얻는 방법은 지정하지 않음
로 나뉜다. 보통 선언적 DML 이 일반적으로 절차적 DML 보다 배우기 쉽고 사용하기 쉽다. 하지만 사용자가 데이터를 얻는 방법을 명시하지 않기 때문에 DBMS 가 효울적인 데이터 접근 방법을 스스로 결정해야 한다.
Query
쿼리는 정보를 조회하는 요청문이다. DML 에서 정보 조회와 관련된 부분을 Query Language 라고 한다.
정확하지 않지만, 일반적으로 쿼리 언어와 데이터 조작어를 동일하게 보기도 한다.
SQL DML
SQL은 비절차적 언어이며, 쿼리를 날릴 때 여러 테이블로부터 입력을 받고, 항상 단일 테이블을 반환하도록 되어 있다.
select instructor.name
from instructor
where instructor.dept_name = 'History';Database Access from Application Programs
SQL 과 같은 비절차적 쿼리 언어는 범용 튜링 기계 만큼 강력하진 않다. 이는 프로그래밍 언어로 할 수 있는 연산들은 SQL 로는 불가능 할 수 있다는 것이다.
이러한 걸 극복하기 위해 어플리케이션 프로그램이 DB 와 상호작용하는 프로그램을 말하고, 개발되게 된다. DB 에 접근하려면 DML 문을 호스트에서 DB로 전송하여 실행해야 한다(API 사용).
- ODBC: C 및 여러 언어에서 사용가능한 어플리케이션 프로그램 인터페이스 수준
- JDBC: Java 언어에서 사용할 수 있는 인터페이스 표준
MySQL
여기서는 우선 MySQL 을 사용하며, 관계형 DB 이다. 이름에서 보다시피 SQL 을 사용하게 되며, 웹어플리케이션 스택에 널리 사용되어 진다(LAMP 스택).
MySQL 5.x - 널리 사용되던 안정 버전 - 기본 캐릭터셋: latin1 - JSON 타입 미지원 (5.7부터 지원)
MySQL 8.0 (현재 최신 LTS 버전) - 기본 캐릭터셋: utf8mb4 - CHECK 제약조건 완전 지원 (8.0.16부터) - 윈도우 함수 지원 - 개선된 성능과 보안 - 새로운 인증 플러그인 (caching_sha2_password)
이를 실습하기 위해 Docker 을 이용해 구성해보자.
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=1234 mysql:8.0d 는 백그라운드 옵션, p는 포트 설정, e는 환경 변수를 설정할 수 있게 한다. 두번째 인자로는 가져올 이미지 이름과 그에 해당하는 태그를 달 수 있다.
도커는 이러한 프로그램을 image 형태로 제공하여 다수의 사용자에게 간편하게 프로그램을 올릴 수 있도록 한다.
나는 Docker Desktop 에 이미 다운받은 이미지가 있어서 그걸로 구동했다.
Docker Compose
매번 위 옵션들을 다 치기에는 버거울 수 있다.
도커는 docker-compose.yml 을 통해 쉽게 도커를 실행할 수 있도록 한다.
version: "3.8"
services:
ms-mysql-practice:
image: mysql:latest
container_name: ms-mysql-container
restart: always
environment:
MYSQL_ROOT_PASSWORD: "1234"
MYSQL_DATABASE: "liondb"
MYSQL_USER: "lion"
MYSQL_PASSWORD: "1234"
TZ: Asia/Seoul
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
volumes:
- ./database/init/:/docker-entrypoint-initdb.d/
- ./database/datadir/:/var/lib/mysql
platform: linux/x86_64
ports:
- 3306:3306생소한 명령어를 파헤쳐보자.
컨테이너가 MySQL 서버를 시작할 때 추가 옵션을 전달하는 부분
- –character-set-server=utf8mb4
- MySQL 서버의 기본 문자셋(charset)을 utf8mb4로 설정
- utf8mb4는 모든 유니코드 문자를 포함할 수 있어서 이모지, 특수문자도 저장 가능
- –collation-server=utf8mb4_unicode_ci
- 기본 정렬 규칙(collation)을 utf8mb4_unicode_ci로 설정
- 대소문자를 구분하지 않고(ci = case-insensitive) 유니코드 기준으로 문자열 비교
호스트와 컨테이너 내부 디렉토리를 연결하는 부분
- ./database/init/:/docker-entrypoint-initdb.d/
- 컨테이너 시작 시 MySQL이 docker-entrypoint-initdb.d/ 안에 있는 SQL 파일이나 스크립트를 자동으로 실행
- ./database/datadir/:/var/lib/mysql
- MySQL의 실제 데이터가 저장되는 디렉토리
- 호스트 디렉토리(./database/datadir/)와 연결해서 컨테이너가 삭제되어도 데이터 유지
이제 접속은 터미널에서 다음을 입력하면 된다.
docker exec -it ms-mysql-container mysql -ulion -p1234 liondb
여기서 exec 는 이미 실행중인 컨테이너 안에서 명령어를 실행할 때 사용하며
-interactive, -tty 옵션을 통해 STDIN 으로 사용자의 입력을 받고, 터미널 환경을 에뮬레이션하여 명령어 실행 결과가 깔끔하게 보이도록 한다.
ms-mysql-container 한테 명령어 mysql -ulion -p 1234 liondb 를 실행하라는 명령이며, liondb 라는 데이터베이스를 사용할 수 있게 된다.